


Choosing a cloud data platform can feel a bit like picking a favorite ice cream flavor while standing in a blizzard: there are lots of options, each promising to be the best for different cravings. Snowflake, Databricks, and Google BigQuery dominate the conversation, and each brings distinct strengths in performance, pricing, and developer experience. In this guide you’ll get a clear, practical comparison of their architectures, cost models, best-fit use cases, and migration considerations so you can decide which platform will actually help your team move faster (and sleep better).
Why this comparison matters
Data powers modern products and decisions. The platform you choose affects query speed, analytics agility, machine learning pipelines, and your cloud bill — sometimes dramatically. Picking the wrong option can mean slower time-to-insight, ballooning costs, or an overcomplicated architecture that only your most patient engineer understands.
We’ll walk through how Snowflake, Databricks, and BigQuery differ technically and operationally, and give practical guidance for selecting the right tool based on workload, team skills, and cost sensitivity. Along the way, we’ll reference recent analyses and comparisons so you can validate trade-offs with up-to-date info.
Quick platform overviews
Snowflake
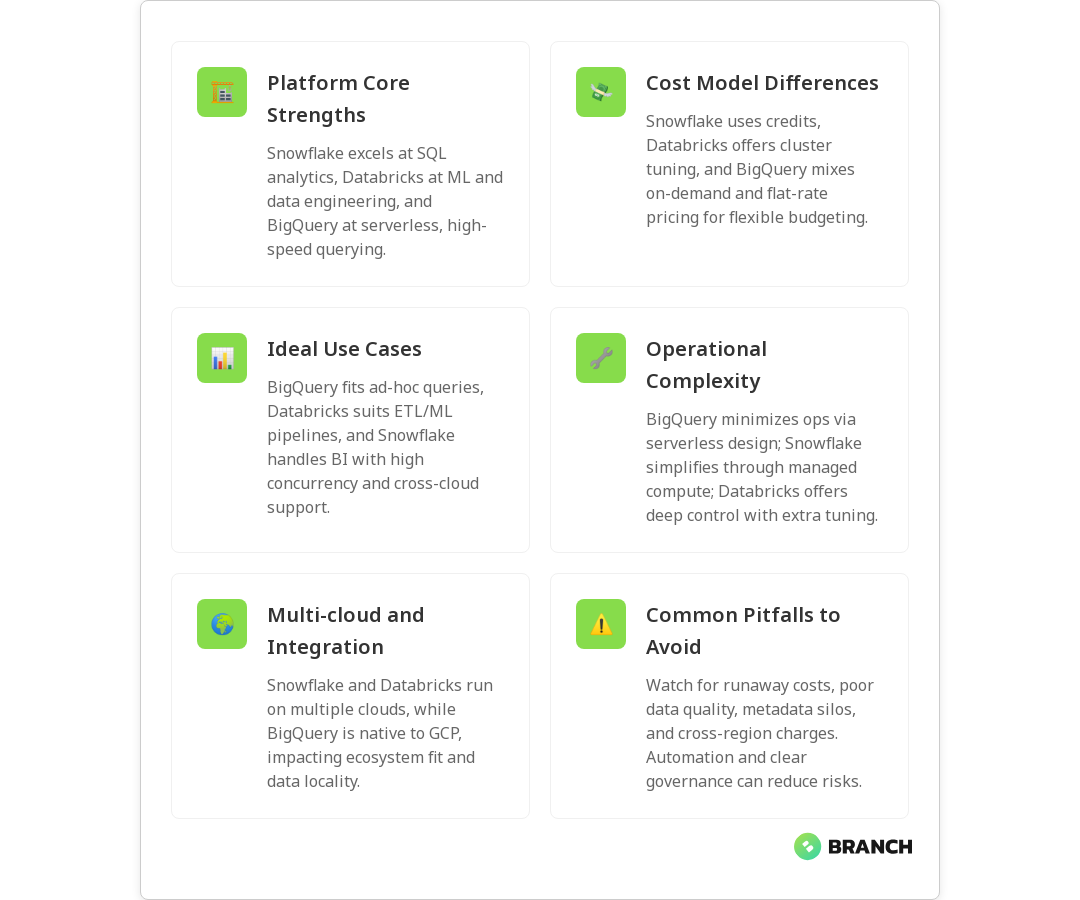
Snowflake is a cloud-native, data warehouse-focused platform known for its separation of storage and compute, multi-cluster warehouses, and an SQL-first user experience. It’s engineered for rapid analytics, concurrency, and scale without much infrastructure tinkering. Snowflake’s credit-based pricing and capacity discounts reward predictable usage or pre-purchased capacity, and features like Snowpipe and Materialized Views help with near-real-time ingestion and faster query response.
For a recent cost and performance look at Snowflake relative to alternatives, check this concise comparison.
keebo.ai breakdown — a recent practical analysis of cost and performance trade-offs.
Databricks
Databricks started in the world of big data and ML with Apache Spark at its core. Today it’s a unified analytics platform that blends data engineering, machine learning, and analytics. Databricks shines when you need robust data pipelines, Delta Lake for ACID transactions on data lakes, and integrated ML lifecycle tools (like Delta Live Tables and Model Serving). If you want tight control over cluster behavior, autoscaling clusters and governance policies offer that flexibility.
BigQuery
Google BigQuery is a fully managed serverless data warehouse with a “just run your SQL” vibe. It excels at rapid ad-hoc queries on huge datasets, and its on-demand pricing and flat-rate options simplify cost models for different teams. BigQuery’s serverless nature reduces operations overhead, and it integrates tightly with Google Cloud’s ecosystem for analytics and ML.
For a direct comparison between BigQuery and Snowflake, this explainer is clear and practical.
DataCamp comparison — useful context on performance and pricing differences.
Performance and cost: trade-offs you need to know
Performance and cost are the twin lenses through which many decisions are made. The right choice depends on query patterns, concurrency needs, data freshness, and whether you run heavy ML workloads or mostly BI queries.
- Snowflake: Predictable scaling and concurrency with multi-cluster warehouses. Good for mixed analytic workloads where many users run SQL queries concurrently. You pay for compute credits and storage separately.
- Databricks: Excellent for ETL, streaming, and ML workloads thanks to Delta Lake and Spark optimizations. You manage clusters (though autoscaling helps) and can tune them for cost vs performance. Databricks often shines when you care about unified pipelines rather than pure query latency.
- BigQuery: Serverless with strong query throughput and instant scaling. On-demand pricing is great for sporadic queries; flat-rate slots can reduce costs for high-volume, predictable workloads. Serverless means less infrastructure management, which is a cost savings in engineering time.
Best-fit use cases
Here’s a practical way to think about which platform to pick depending on the job at hand:
- BI and analytics at scale (many concurrent users, SQL-heavy): Snowflake or BigQuery. Snowflake’s concurrency features and BigQuery’s serverless scaling both work well; pick based on ecosystem and pricing preference.
- Data engineering, ELT/ETL, streaming, and ML model production: Databricks. Delta Lake + integrated ML capabilities reduce friction across the pipeline.
- Ad-hoc analytics with minimal ops overhead: BigQuery. If you don’t want to manage clusters or compute pools, serverless is attractive.
- Hybrid/multi-cloud flexibility: Snowflake, since it’s cloud-agnostic across AWS, Azure, and GCP.
Integration, migration, and architecture considerations
Moving to a new data platform is rarely a lift-and-shift — it’s typically an evolution: rethinking ETL patterns, governance, security, and orchestration.
- Data locality and cloud provider lock-in: BigQuery is GCP-native; Snowflake and Databricks run on multiple clouds (Databricks is strong on AWS and Azure as well), but integrations and managed features vary by cloud. Consider where your other systems live.
- Existing skills: If your team is SQL-first, Snowflake or BigQuery may have shorter ramp-up. For Spark-savvy teams focused on ML and complex transformations, Databricks will feel more natural.
- Operational model: Serverless (BigQuery) reduces ops work. Snowflake reduces operational complexity with managed warehouses. Databricks provides deep control for ML pipelines but requires cluster management (mitigated by autoscaling).
- Data governance: All three support encryption and role-based access, but details around fine-grained access and cataloging can differ. Plan for a metadata layer and consistent governance approach regardless of platform.
Common challenges and how to avoid them
Every platform has its pitfalls. Here’s practical advice to dodge the common ones:
- Uncontrolled costs: Watch interactive queries, frequent small jobs, and forgotten compute clusters. Implement usage guardrails, alerts, and FinOps practices early.
- Poor data quality: Garbage in, garbage out still applies. Invest in data validation, observability, and ownership models so bad data doesn’t become a recurring incident.
- Fragmented metadata: Without a central catalog, teams duplicate efforts. Adopt a shared data catalog and documentation practices.
- Underestimating egress and cross-region costs: Cloud provider pricing details matter — especially if you move data across clouds or regions frequently.
Trends and the near-term future
Over the next few years you should expect:
- More convergence: Platforms will continue adding features that blur lines — Snowflake adding table formats that resemble lakehouse ideas, Databricks improving SQL and warehousing features, and BigQuery extending ML-first workflows.
- Focus on open formats: Delta Lake, Apache Iceberg, and open table formats will reduce lock-in and encourage portable data lakes/lakehouses.
- Cost management tooling: Better native FinOps features and third-party tools will become standard as teams demand predictable cloud spend.
- Tighter ML integration: Expect deeper first-class ML support (model registries, feature stores, model serving) embedded in data platforms.
How to pick: a short decision checklist
- What’s the primary workload? (BI queries, ETL, streaming, ML)
- Where do your other systems live? (GCP, Azure, AWS, multi-cloud)
- How predictable is your query load? (predictable → reserved capacity; spiky → serverless/autoscale)
- What skills does your team already have? (SQL, Spark, data engineering)
- How important is operational simplicity vs. control?
- Can you run a short proof-of-concept on a subset of real workloads?
Run that PoC. It will reveal hidden costs, performance quirks, and predictable pitfalls faster than any sales deck.
FAQ
What is a data cloud platform?
A data cloud platform is a managed environment that stores, processes, and serves data at scale in the cloud. It combines storage, compute, security, and analytics or ML services so teams can run queries, pipelines, and models without managing physical infrastructure.
Which cloud platform is best for data analysts?
For SQL-first analytics with minimal operations, BigQuery and Snowflake are typically the best fits. BigQuery is strong for serverless, ad-hoc queries and GCP-native workloads; Snowflake provides multi-cloud support, strong concurrency, and a robust SQL experience.
Is Snowflake a cloud platform?
Yes. Snowflake is a cloud-native data platform (often described as a cloud data warehouse) running on AWS, Azure, and Google Cloud. It provides managed storage, compute, and analytics features designed for scalability and data sharing.
Is Databricks a cloud platform?
Yes. Databricks is a unified analytics platform built around Apache Spark. It’s available as a managed service across major cloud providers and is focused on scalable data engineering, machine learning, and advanced analytics workloads.
What is the most used cloud data platform?
Usage depends on region, industry, and workload. BigQuery is common in Google Cloud environments, Snowflake is widely adopted across multi-cloud enterprise analytics, and Databricks is strong in data engineering and ML. The “best” choice depends on workloads and team skills.
Choosing between Snowflake, Databricks, and BigQuery is less about declaring a winner and more about matching platform strengths to your workloads, skills, and cost profile. Run tests, agree on governance, and remember: a great data strategy and solid pipelines will make any platform sing.


