


Data mesh is a phrase you’ve probably heard at least once in a meeting that promised to “fix everything” about data. It’s more than buzzword bingo, but less than a magical one-size-fits-all cure. In this article I’ll unpack what data mesh actually means, why organizations are excited about it, where teams trip up, and practical steps to decide whether it belongs in your data strategy. By the end you’ll have a clear picture of the principles, trade-offs, and real-world considerations so you can stop nodding politely and start planning intentionally.
Why data mesh matters now
Companies are drowning not in data, but in poorly organized data—siloed teams, clogged pipelines, inconsistent definitions, and a small central team trying to serve everyone’s requests. Data mesh reframes the problem: instead of centralizing everything in a giant warehouse, it distributes ownership to the teams who understand the domain best. That shift promises faster delivery, better data products, and less friction between engineers, analysts, and business owners.
This idea has gained traction across industry commentary and vendor writing; for a concise primer, see the overview on Wikipedia or Oracle’s practical explainer on domain-oriented ownership and self-service platforms at Oracle.
What data mesh actually is
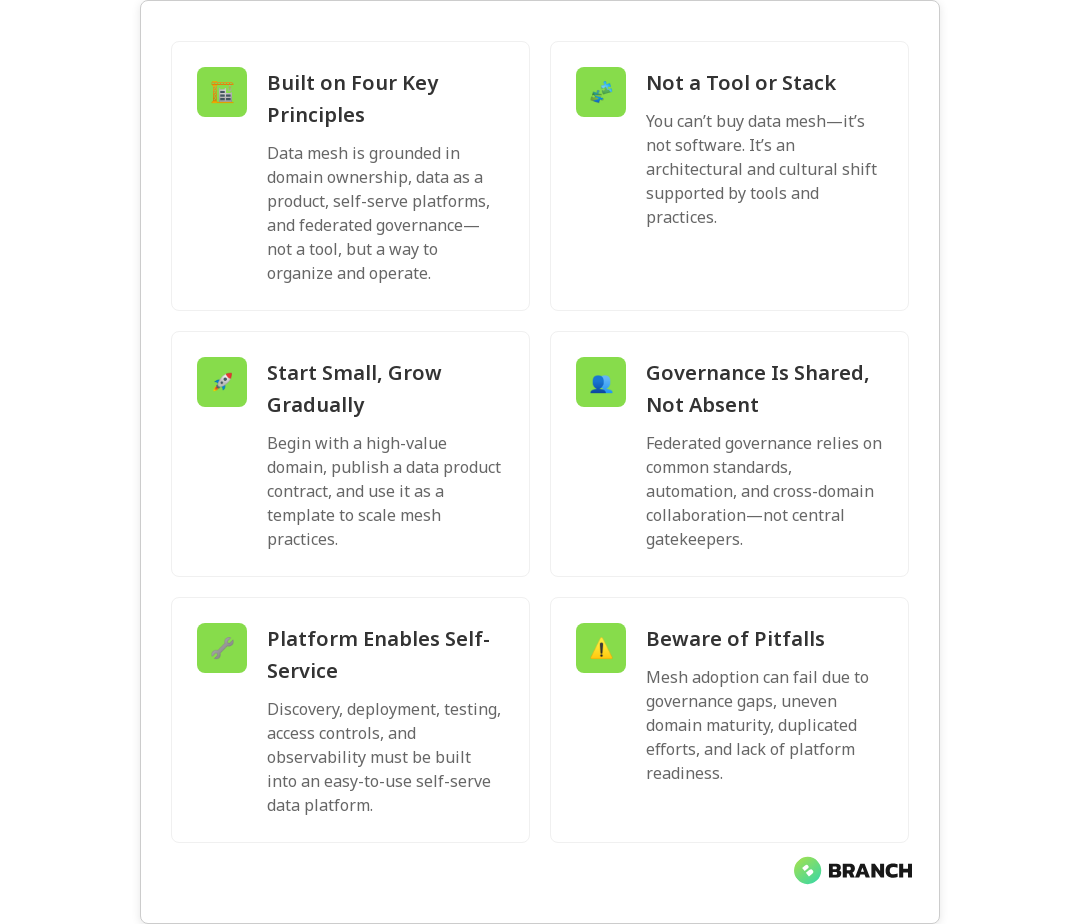
At its core, data mesh is an organizational and architectural approach that rests on four primary principles:
- Domain ownership: Data responsibility is pushed to the teams closest to the source (the domain teams), rather than a centralized data team owning every dataset.
- Data as a product: Domains treat their data outputs like products—with discoverability, documentation, SLAs, and a product mindset toward consumers.
- Self-serve data platform: A reusable platform provides tools, infrastructure, and automation so domain teams can publish reliable data products without reinventing the wheel.
- Federated computational governance: Governance is enforced through shared policies, standards, and automated checks rather than a single gatekeeping team.
These principles come from several recognized descriptions and industry guides; for example, IBM summarizes the domain-based and cloud-native aspects of the pattern in their overview at IBM.
What data mesh isn’t
There are a lot of misconceptions floating around. Data mesh is not:
- A technology stack: You don’t buy data mesh as a product. It’s an organizational pattern supported by tooling.
- An excuse to avoid governance: Decentralization without governance equals chaos. Mesh demands federated governance—shared rules, metadata standards, and automated validation.
- Instant scale: It can take time to make distributed ownership work; the upfront effort in coordination and platform-building is real.
Starburst and Monte Carlo have clear write-ups on common myths—useful reads if you want to avoid the classic “we decentralized and now no one knows where the data is” problem (see Starburst and Monte Carlo).
How data mesh compares to other architectures
When people ask if data mesh is a data warehouse, lakehouse, or fabric, the answer is: “No — and it can work with them.” Think of mesh as an organizational overlay rather than a replacement for storage or compute patterns.
- Data warehouse vs. data mesh: Warehouses centralize curated data in one place. A data mesh decentralizes ownership and distributes curated outputs across domains. You might still run many domains’ data products into a shared warehouse for analytics, or you might keep them in domain-owned stores accessible via standardized APIs.
- Lakehouse vs. data mesh: Lakehouses blend lake and warehouse concepts at the storage/compute layer. Mesh focuses on who owns and governs the data products that may live in a lakehouse, warehouse, or across multiple storage systems.
Oracle’s explainer highlights how mesh complements these architectures by emphasizing domain-oriented ownership and self-service access to data, rather than prescribing a specific storage model (see Oracle).
Practical strategies for adopting data mesh
Moving to a data mesh is as much about people and process as it is about technology. Here’s a practical roadmap that teams have found useful:
- Define the domains and prioritize: Map business domains (sales, product, supply chain) and choose one or two to pilot. Pick domains where the business impact is clear.
- Create a data product contract: Require each domain to publish a short contract for their data product—what it contains, consumers, update cadence, quality expectations, and contact owner.
- Build a self-serve platform incrementally: Start with essential capabilities: data discovery, cataloging, CI/CD for data pipelines, observability, and access controls. Don’t try to solve everything at once.
- Establish federated governance: Form a lightweight council with domain reps and platform engineers to agree on standards and automated checks.
- Measure and iterate: Track product-level KPIs like consumer adoption, MTTR (mean time to repair), data product uptime, and time-to-delivery for new data features.
Organizational impact and governance
Data mesh shifts accountability. Domain teams must get comfortable owning production data—this often requires cultural changes, reskilling, and incentives aligned with data product quality. Governance moves from policing to enabling: automated policy enforcement, clear standards, and tooling that helps domains comply rather than bog them down.
A federated governance model should include:
- Common metadata and cataloging standards
- Privacy and compliance guardrails codified in the platform
- Automated lineage and observability to troubleshoot quickly
- Shared SDKs and templates to lower adoption cost
Technical considerations: platform and tooling
A self-serve data platform is the plumbing of a mesh. It should provide:
- Discovery and catalog tools so consumers find and evaluate data products.
- Pipeline templates and CI/CD for data product delivery.
- Automated testing, lineage, and monitoring for quality and observability.
- Access control, encryption, and policy enforcement integrated with identity systems.
Whether you build the platform on cloud services, open-source tools, or a mix depends on skills, budget, and governance needs. Cloud providers and vendor solutions can accelerate time-to-value, but you still need organizational alignment and strong product contracts.
Read more: Cloud infrastructure services – for guidance on designing scalable and secure cloud environments that underpin a reliable self-serve data platform.Pitfalls and downsides
Data mesh promises a lot, but there are real drawbacks if you rush in without preparation:
- Uneven maturity: Domain teams vary in their ability to produce and sustain data products. Without training and templates, quality will be inconsistent.
- Duplicate work: Without clear standards and reusable components, teams can rebuild similar pipelines and tooling, increasing cost.
- Governance gaps: Federated governance requires automation and agreement—without it, you end up with fragmented security and compliance exposure.
- Initial overhead: Building a self-serve platform and setting cultural incentives takes time and investment up front.
Monte Carlo and Starburst both call out how organizational readiness and tooling maturity are often underestimated – read their posts if you want cautionary tales and practical warnings (see Monte Carlo and Starburst).
Read more: Data engineering services – if you’re considering external help to stand up pipelines, governance, and the platform components while your teams transition.Trends and where data mesh is headed
Expect the ecosystem to mature along three axes:
- Better platform components: More out-of-the-box tools for discovery, lineage, and policy-as-code will reduce the custom build burden.
- Stronger metadata interoperability: Standards and catalogs will improve cross-domain discoverability and reduce duplication.
- Hybrid adoption patterns: Many organizations will adopt mesh principles selectively—combining centralized and decentralized approaches where each fits best.
In short: data mesh is evolving from a bold idea into a set of practical patterns and products you can adopt incrementally.
FAQ
What is a data mesh?
A data mesh is an organizational and architectural approach that decentralizes data ownership to domain teams, treats data as a product, provides a self-serve platform, and uses federated governance to maintain standards and compliance.
What are the four principles of data mesh?
The four principles are domain ownership, data as a product, a self-serve data platform, and federated computational governance. These are the pillars that guide how teams structure ownership, delivery, and governance.
What is the difference between data warehouse and data mesh?
A data warehouse is a centralized storage and compute architecture optimized for analytics. Data mesh is an organizational design that can work with or alongside warehouses: mesh decentralizes who owns and publishes curated data products, while a warehouse remains a place where data might be stored or consumed.
What is the difference between data lakehouse and data mesh?
A lakehouse is a technical architecture combining lake and warehouse features at the storage level. Data mesh is about ownership and governance across domains; a lakehouse can be the backing store for domain data products in a mesh, but doesn’t by itself enforce distributed ownership or product thinking.
What are the downsides of data mesh?
Downsides include organizational readiness requirements, potential duplication of effort, uneven data product quality across domains, upfront investment to build the self-serve platform, and the need for automated governance to ensure compliance and security.
Data mesh is not a silver bullet, but for organizations willing to invest in people, process, and a reliable platform, it can reduce bottlenecks and create more usable data. If you’re thinking about taking steps toward mesh, start small, enforce standards with automation, and measure product-level outcomes—then expand what works, not what sounds trendy.
Curious to explore hands-on help with pipelines, platforms, or AI built on strong data foundations? We help teams design practical approaches that match their culture and goals—no mesh-shaped hammer required.


