Machine learning powers everything from your phone’s photo sorting to complex fraud detection systems. But not all ML is created equal — some models need lightning-fast responses while others can be trained and run on a schedule. In this article you’ll learn the practical differences between real-time (online/streaming) ML and batch ML, when each approach makes sense, and how to design systems that balance speed, cost, and accuracy.
Whether you’re building personalized recommendations, monitoring system health, or deciding how fresh your training data needs to be, this guide will walk you through decision criteria, architecture options, operational tradeoffs, and helpful tips for production-ready ML. Expect clear examples, friendly advice, and a little humor to keep the cloud bill from giving you nightmares.
Why the distinction matters
Choosing between real-time and batch ML affects architecture, cost, operational complexity, and user experience. Real-time ML minimizes latency and enables instant decision-making — ideal for scenarios where speed changes outcomes. Batch ML reduces operational overhead and often lets you work with larger datasets more efficiently, which can improve model accuracy when immediate responses aren’t required.
The right choice influences everything downstream: data pipelines, feature engineering, model evaluation cadence, monitoring, and the team skills you’ll need. Picking the wrong mode can produce slow responses, expensive infrastructure, or stale predictions that hurt your business — and nobody wants that.
What is real-time ML?
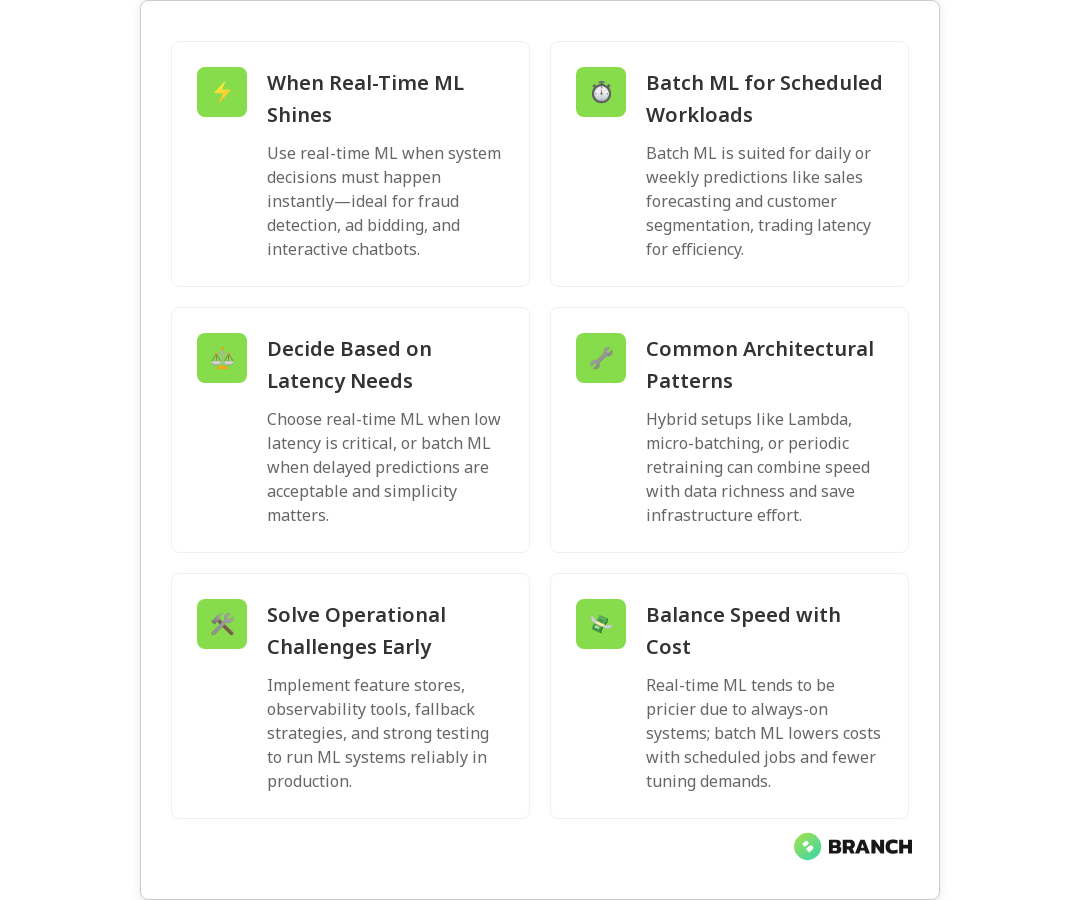
Real-time ML (also called online or streaming ML) processes data and emits predictions with minimal delay. Typical latencies range from milliseconds to a few seconds. Use real-time ML when decisions must be immediate or when models must adapt quickly to new data patterns.
Common real-time ML use cases
- Fraud detection during a payment transaction — block or flag suspicious behavior instantly.
- Ad bidding and personalization — show the right creative while the user is on site.
- Real-time monitoring and anomaly detection for infrastructure or IoT devices.
- Chatbots and conversational agents that require instant context-aware replies.
What is batch ML?
Batch ML processes data in groups on a schedule — hourly, daily, weekly — and typically retrains models or generates predictions for downstream reporting or offline systems. Latency is measured in minutes to days, and workflows are optimized for throughput and resource efficiency rather than speed.
Common batch ML use cases
- Daily sales forecasting used for inventory planning.
- Monthly customer segmentation and churn modeling for strategic marketing.
- Large-scale model retraining that needs entire datasets for feature engineering and validation.
- Data warehouse analytics and business intelligence where immediate answers aren’t required.
Decision criteria: When to choose each approach
Here are practical factors to weigh when picking real-time versus batch:
- Latency needs: If decisions must happen immediately, choose real-time. If minutes or hours are acceptable, batch is usually fine.
- Data volume and velocity: High-velocity streams often push you toward streaming architectures; large historical data favors batch processing for training.
- Model freshness: Real-time supports continuous updating and quick adaptation to drift; batch relies on periodic retraining.
- Cost: Real-time systems typically require more always-on infrastructure and more complex pipelines, which increases cost. Batch can leverage spot instances and scheduled workloads for savings.
- Complexity and time to market: Batch ML is typically faster to implement and easier to debug. Real-time adds complexity: low-latency feature stores, streaming joins, and stricter testing.
- User experience impact: If prediction freshness materially changes UX (e.g., live recommendations), favor real-time.
- Regulatory and audit needs: Batch processes can be easier to reproduce and audit, which helps with compliance and explainability.
Architectures and hybrid approaches
The modern reality is often hybrid. You might use batch training to build robust models from historical data and then deploy them into a real-time inference layer. Several architectural patterns help balance the tradeoffs:
- Lambda architecture: Maintains both batch and real-time layers so you can get low-latency views and periodically recompute accurate results.
- Kappa architecture: Focuses on streaming everywhere, keeping a single code path for both historical reprocessing and real-time processing.
- Micro-batching: Processes small time-windowed batches (seconds to a few minutes) to reduce overhead while approaching real-time latency.
- Model serving with periodic retrain: Serve models in real time but retrain on a batch schedule to incorporate new data and reduce drift.
- Online learning: Some algorithms update weights incrementally as new data arrives — useful when you need continual adaptation but want to avoid full retraining.
Each pattern requires different tooling and engineering disciplines. Real-time layers often rely on streaming platforms and low-latency feature lookups; batch layers rely on robust ETL, data lakes, and distributed training.
Operational considerations
Operationalizing ML is where projects often stall. Here are the top operational topics to address early:
- Feature stores: Centralize feature definitions to ensure parity between training and serving, especially critical for low-latency real-time features.
- Monitoring and observability: Track data drift, model performance, latency, and resource utilization. Alerts should trigger retraining or rollback workflows.
- Testing and reproducibility: Unit and integration tests for data pipelines and models; reproducible training pipelines for audits.
- Scalability: Design for peak load — real-time inference services must scale horizontally; batch training may require distributed compute like GPUs or clusters.
- Fallback strategies: Serve safe default predictions or heuristics when model latency spikes or data is incomplete.
- Security and privacy: Mask or anonymize sensitive data and ensure compliance when streaming user information in real time.
Cost and tradeoff analysis
Real-time systems tend to increase operational costs because of always-on infrastructure, higher IOPS, and the need for specialized engineers. Batch systems reduce compute peaks by scheduling heavy jobs and are often cheaper to run. When evaluating total cost of ownership, consider:
- Cloud compute and networking costs for streaming vs scheduled jobs.
- Engineering and maintenance overhead for low-latency pipelines.
- Business impact of faster decisions — sometimes faster predictions increase revenue enough to justify higher cost.
- Potential cost-savings from hybrid approaches like micro-batching or asynchronous precomputation.
Practical examples and patterns
E-commerce personalization
Batch approach: Generate nightly segments and recommendations based on aggregated behavior. Cheaper and easier to audit, but may miss trending products.
Real-time approach: Update recommendations based on current session behavior, cart updates, and recent clicks. Higher conversion potential but more complex infrastructure and feature management.
Fraud detection
Batch approach: Analyze historical fraud patterns to refine scoring models and rules on a daily cadence.
Real-time approach: Score transactions in-flight to block fraudulent payments instantly, often combining model scores with fast rule engines.
Predictive maintenance
Batch approach: Run heavy analytics on accumulated sensor data to plan maintenance cycles.
Real-time approach: Trigger alerts when anomaly detectors observe sudden changes in streaming telemetry.
Common challenges and how to manage them
- Data inconsistencies: Ensure the same feature computations are used at training and serving. Use a feature store and enforce schemas.
- Model drift: Monitor model performance over time; automate retraining triggers for drift detection.
- Pipeline fragility: Add retries, backpressure, and graceful degradation to streaming systems.
- Testing: Implement synthetic and production shadow testing to validate models under load without impacting users.
- Skill gaps: Building real-time systems often demands experience in distributed systems, streaming technologies, and observability.
FAQ
What is an example of machine learning?
Examples include image recognition, product recommendations, fraud detection, and sales forecasting — systems that learn from data to improve outcomes.
What are types of machine learning?
The main types are supervised, unsupervised, and reinforcement learning. Subfields include semi-supervised, self-supervised, and online/real-time learning.
What is machine learning with real-time example?
A real-time ML example is fraud detection during online payments, where a model scores transactions instantly to block suspicious activity.
Is machine learning the same as AI?
Machine learning is a subset of AI. AI is the broader field of intelligent systems, while ML specifically refers to algorithms that learn from data.
What is deep learning vs machine learning?
Deep learning uses neural networks with many layers to handle complex data like images and text. Traditional ML methods work well on structured data with lower compute needs.
Final thoughts
There’s no universal winner between real-time and batch ML — only the right tool for the job. Start by identifying the business requirement for latency, accuracy, and cost. Favor batch when operations simplicity and cost efficiency matter, and pick real-time when speed drives business outcomes. In many practical systems, a hybrid approach gives you the best of both worlds: robust models trained on large batches, served with low-latency layers that keep experiences fresh.
If you’re designing ML products and want help balancing architecture, data pipelines, and operational needs, consider partnering with teams experienced in both data engineering and production ML. They’ll help you avoid common pitfalls and pick an approach that scales with your goals — and keep your cloud bill from becoming a villain in your product story.