Deciding where to store your company’s data can feel like choosing a new kitchen: do you want raw ingredients piled in a pantry (flexible but messy), neatly organized cabinets for quick cooking, or a hybrid space that’s part pantry, part chef’s prep station? In data terms, those choices map to data lakes, data warehouses, and the newer data lakehouse. This article breaks down what each is, when to use them, the technical trade-offs, and how to choose a path that supports analytics, machine learning, and business reporting.
What they are – short and useful definitions
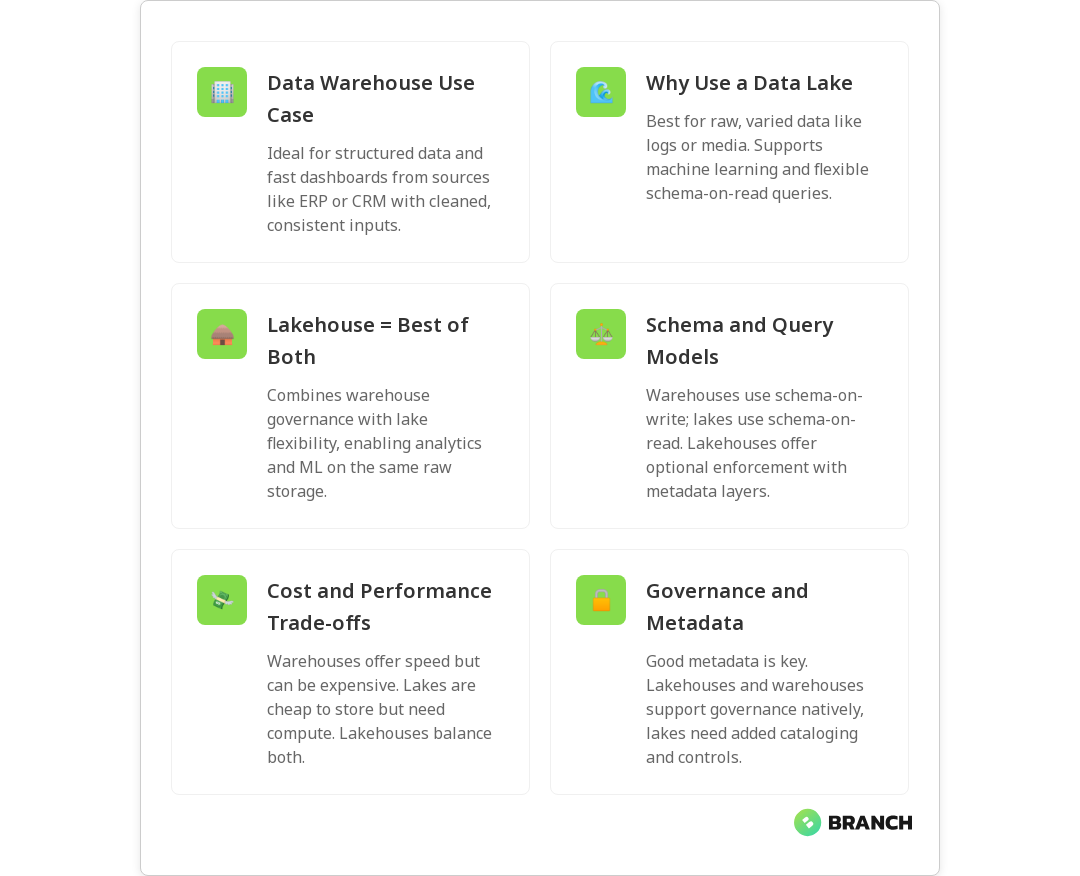
Data Warehouse
A data warehouse is a structured, curated repository optimized for business intelligence and reporting. It stores cleaned, transformed, and modeled data in predefined schemas so analysts can run fast SQL queries and generate consistent dashboards. Think of it as a tidy, labeled pantry: everything is organized for quick consumption. For a clear comparison of use cases, see IBM’s overview of warehouses, lakes, and lakehouses.
Data Lake
A data lake stores raw, often unstructured or semi-structured data at scale. It’s inexpensive and flexible, accepting everything from application logs and sensor data to images and JSON files. Data scientists and engineers favor lakes for exploratory analysis and machine learning because you can retain original data and transform it later (ELT-style). Microsoft Azure explains how lakes support varied data types and data science workloads in detail.
Data Lakehouse
The lakehouse blends the best of both worlds: the cost and flexibility of a lake with many of the governance, transactional, and performance features of a warehouse. Lakehouses add a metadata and management layer on top of object storage so you can run BI queries reliably while still enabling ML workflows on raw data. IBM and several industry posts describe how lakehouses aim to support both analytics and ML with transactional guarantees.
When to choose each: practical business scenarios
- Choose a data warehouse if your primary need is stable, fast reporting and dashboards built on cleaned, structured data from a few standardized sources (ERP, CRM, sales systems).
- Choose a data lake if you need to ingest diverse, high-volume raw data (logs, IoT, media) for discovery, experimentation, and large-scale model training – and you don’t need immediate consistency for BI queries.
- Choose a data lakehouse if you want one platform that supports both exploratory ML and governed analytics, especially when you must reduce operational overhead of maintaining separate lake and warehouse systems.
Real-world teams often use more than one pattern. A common approach is to ingest everything into a data lake and then curate extracts into a warehouse for business reporting. Lakehouses try to collapse that two-step pattern into a single, more maintainable architecture, supporting both ETL and ELT and even streaming workloads, as explained in Striim’s overview.
Read more: Data Engineering for AI – This explains why a sound data pipeline is essential whether you pick lake, warehouse, or lakehouse.Technical differences that matter
Schema and structure
Warehouses use schema-on-write: data is modeled and validated before it’s stored. This enables consistent, performant queries for dashboards. Lakes use schema-on-read: data is stored raw and interpreted when read – flexible but potentially messy. Lakehouses introduce structured metadata and optional schema enforcement so you can have schema evolution without losing the benefits of raw storage.
Transactions and consistency
One historical advantage of warehouses is transactional integrity (ACID) for updates and deletes; lakes lacked this, making governance and consistent views harder. Lakehouse projects add transactional metadata layers to provide ACID-like features on top of lake storage, enabling reliable analytics and reducing surprise results during reporting, as noted by DATAVERSITY.
Performance and cost
Warehouses excel at fast, concurrent SQL queries, but that performance often comes at higher storage and compute costs. Lakes are cost-effective for storing petabytes of raw data but require additional compute for querying. Lakehouses aim to balance cost by using lower-cost object storage with query engines and caches that accelerate common workflows. Amplitude’s discussion highlights how lakehouses support both structured querying and raw data access without duplicating storage.
Governance and security
Governance tends to be easier in warehouses because the data is curated and structured. Lakes require robust metadata, cataloging, and access controls to avoid becoming a data swamp. Lakehouses typically integrate metadata layers and governance controls to make secure, auditable access easier while still enabling data science workflows.
Migration and integration strategies
Migrations are rarely “lift-and-shift.” The practical playbook often looks like this:
- Inventory and classify your data sources (structured, semi-structured, unstructured).
- Define business domains and prioritize what must be curated for dashboards vs what can stay raw for ML.
- Choose ingestion patterns: batch ETL for stable sources, streaming for real-time events.
- Implement a metadata/catalog layer and data quality checks early.
- Iterate: start by moving a few high-value datasets and validate queries and access patterns.
Lakehouses make some of these steps simpler by allowing you to keep raw data but still support curated, query-ready tables on top. Tools and platforms vary – but the architectural principles are consistent across vendor recommendations, including Microsoft Azure’s guidance on when lakes are the right fit.
Common challenges and how to mitigate them
- Data sprawl and duplication: Multiple copies across lake and warehouse can cause cost and governance issues. Mitigate by setting a clear “source of truth” policy and using cataloging.
- Skill gaps: Lake and lakehouse work often requires data engineering and platform expertise. Invest in training or partner with specialists.
- Cost surprises: Query engines over object storage can generate unexpected compute costs. Use cost controls, monitoring, and FinOps practices to keep budgets in check.
- Latency needs: Real-time analytics requires streaming ingestion and processing; evaluate platforms that support both streaming and batch without excessive complexity, as Dataversity highlights for IoT and ML scenarios.
Trends and where the market is heading
The lakehouse concept gained momentum because it reduces duplicated effort and supports unified analytics and ML. Expect continued investment in open table formats, standardized metadata layers, and query engines that optimize cost and concurrency. Companies are also pushing for better governance and easier migration paths – a natural market response now that hybrid analytics are a business requirement. IBM and Amplitude both discuss how lakehouses bridge the governance and flexibility gap in modern data architectures.
Another trend is the blending of real-time streaming and batch processing. Platforms that handle both with the same data model allow teams to build real-time features and dashboards without maintaining parallel systems. If your use case includes IoT, personalization, or live monitoring, prioritizing streaming-capable architectures will pay off, as DATAVERSITY explains.
FAQ
What do you mean by data architecture?
Data architecture is the blueprint describing how data is collected, stored, processed, integrated, and accessed across an organization. It covers the physical and logical storage (lakes, warehouses, databases), the pipelines that move data, metadata and governance, and the patterns used for analytics, reporting, and ML.
What is the difference between data architecture and data management?
Data architecture is the high-level design – the “where” and “how” of data flow. Data management is the operational discipline that executes and maintains that architecture: ingestion, quality, cataloging, security, access controls, backups, and lifecycle management. Architecture sets the plan; management runs and governs it.
What is modern data architecture?
Modern data architecture emphasizes flexibility, scalability, and real-time capabilities. It often combines object storage, event streaming, metadata/catalog layers, governed query engines, and ML-ready pipelines. Lakehouse patterns are a prominent modern approach because they support mixed workloads and enable faster insights without managing redundant systems.
What are the three types of data architecture?
Broadly, you can think of three styles: centralized (traditional data warehouse), distributed or decentralized (data mesh approaches), and hybrid (lakes or lakehouses combining centralized governance with federated data ownership). Each has trade-offs in governance, speed of delivery, and operational complexity.
Is data modelling part of data architecture?
Yes. Data modeling is a core activity within data architecture. It defines schemas, relationships, and entitlements for how data should be structured and consumed. Good modeling ensures that analytics are consistent, reliable, and performant, whether those models are applied at write-time (warehouse) or read-time (lake).
Final thoughts
There’s no one-size-fits-all answer. If your immediate need is fast, reliable dashboards, start with a warehouse. If you’re building ML models and need to keep lots of raw, varied data, start with a lake and invest early in metadata. If you want a single system that supports both analytics and ML while reducing duplication, evaluate lakehouse architectures. Industry leaders like IBM and Microsoft provide helpful comparisons as you map requirements to technologies.
Practical next steps: inventory your data sources, prioritize business outcomes (reporting vs model training vs real-time features), and prototype one high-value workflow. That will surface whether you need the governance of a warehouse, the flexibility of a lake, or the hybrid benefits of a lakehouse – and make your migration decisions much less guesswork and a lot more science (or at least well-organized cooking).